
ERD vẽ tay là nợ kỹ thuật trá hình
/ 7 min read
Table of Contents
ERD vẽ tay là nợ kỹ thuật đội lốt tài liệu.
Nó nhìn có vẻ chuyên nghiệp trong buổi review đầu tiên. Có hộp, có mũi tên, có màu sắc, có vẻ như cả team đã hiểu database. Nhưng chỉ cần một migration được merge vào main, sơ đồ đó bắt đầu trượt khỏi sự thật. Một tuần sau nó còn “tham khảo được”. Một tháng sau nó thành lời đồn. Một năm sau nó thành cái bẫy onboarding.
Tôi không nghĩ vấn đề nằm ở việc dev lười viết docs. Dev lười là một cách giải thích quá tiện. Vấn đề thật hơn là: chúng ta đang bắt con người duy trì thủ công một thứ mà hệ thống đã biết rõ hơn con người.
Database schema là sự thật vận hành. ERD chỉ nên là một cách nhìn vào sự thật đó.
Tài liệu chết vì đứng ngoài quy trình
Một tài liệu database thường chết theo ba bước rất quen:
- Ban đầu, ai đó vẽ ERD trong Miro, Draw.io, Excel, Notion hoặc một file PNG rất đẹp.
- Sau đó, team thay đổi schema qua migration, ORM hoặc SQL script.
- Cuối cùng, không ai cập nhật sơ đồ vì việc đó không nằm trong flow review, không có test fail, không có CI nhắc, cũng không ảnh hưởng trực tiếp đến deploy.
Và thế là tài liệu bắt đầu nói dối.
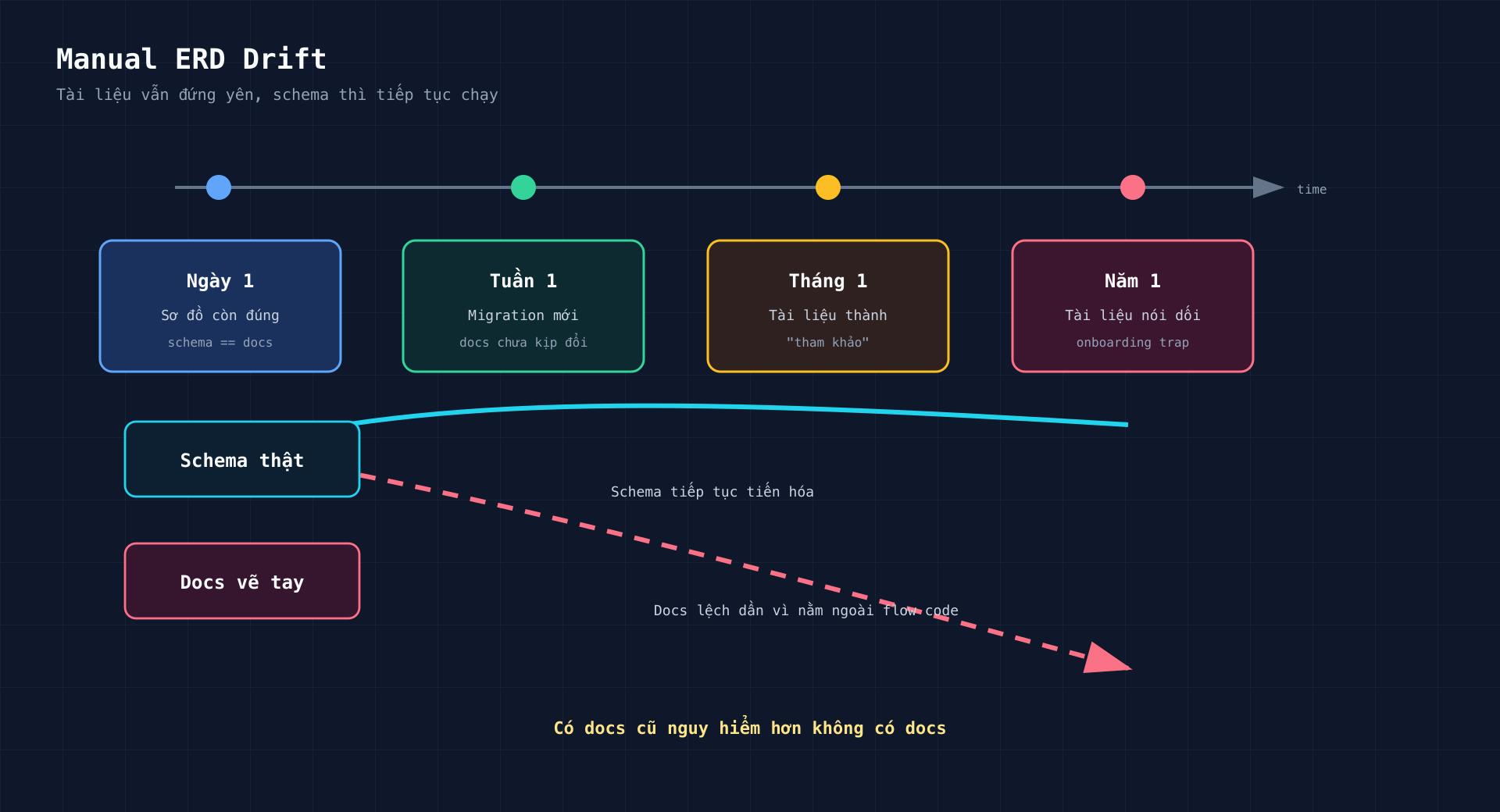
Tài liệu thủ công không hỏng ngay. Nó hỏng từ từ, nên team thường phát hiện quá muộn.
Điều nguy hiểm không phải là thiếu tài liệu. Thiếu tài liệu thì ai cũng cảnh giác. Điều nguy hiểm là có một tài liệu trông đáng tin nhưng đã lệch khỏi hệ thống thật. Nó khiến người mới hiểu sai quan hệ bảng. Nó khiến BA và dev tranh luận trên một hình ảnh cũ. Nó khiến reviewer bỏ sót một foreign key quan trọng vì sơ đồ đẹp quá, chỉ là không còn đúng nữa.
Nếu một tài liệu không được sinh ra từ source of truth, nó sẽ phải cạnh tranh với source of truth. Và nó sẽ thua.
Đừng chăm viết docs hơn, hãy giảm quyền nói dối của docs
Phản xạ phổ biến khi docs lệch khỏi schema là kêu gọi kỷ luật: “Từ nay nhớ cập nhật tài liệu sau khi sửa database”.
Nghe thì đúng. Nhưng trong hệ thống phần mềm, “nhớ làm” là một cơ chế yếu. Những thứ quan trọng không nên phụ thuộc vào trí nhớ và thiện chí. Chúng nên nằm trong pipeline.
Tôi thích cách nghĩ này hơn:
Nếu schema đổi, tài liệu phải đổi. Nếu tài liệu không đổi, CI nên làm team khó chịu.
Đó là lý do tôi thích hướng schema-driven diagram. Không phải vì nó thời thượng, mà vì nó đảo lại vai trò: sơ đồ không còn là một artifact thủ công đứng bên cạnh code. Sơ đồ trở thành output của code.
Liam ERD là công cụ, nhưng ý tưởng mới là phần quan trọng
Liam ERD không chỉ hấp dẫn vì nó render ERD đẹp. Phần đáng giá hơn là nó đối xử với database schema như đầu vào, rồi sinh ra một giao diện có thể tìm kiếm, zoom, filter và highlight quan hệ.
Với public repo, bạn có thể dùng URL dạng liambx.com/erd/p/... để mở schema trực tiếp. Với private repo hoặc CI/CD, bạn dùng CLI để build ERD thành static site.
npx @liam-hq/cli erd build --input ./path/to/schema.sql --format postgresĐiểm mấu chốt không nằm ở câu lệnh trên. Điểm mấu chốt là: từ đây trở đi, sơ đồ có thể được sinh lại bất cứ khi nào schema đổi. Không cần mở tool, không cần kéo thả, không cần export PNG, không cần hy vọng ai đó nhớ cập nhật.
PNG không đủ cho database lớn
Một bức ảnh ERD tĩnh có thể ổn với 12 bảng. Nhưng khi hệ thống lên 80, 100, 150 bảng, ảnh tĩnh bắt đầu phản bội người đọc.
Vấn đề không chỉ là kích thước. Vấn đề là khả năng đặt câu hỏi.
- Bảng
ordersliên quan trực tiếp đến những bảng nào? - Quan hệ giữa
users,roles,permissionsđi qua bảng trung gian nào? - Có bảng nào trở thành “God table” vì quá nhiều bảng phụ thuộc vào nó không?
- Migration mới vừa thêm quan hệ nào vào vùng billing?
Ảnh tĩnh không trả lời tốt các câu hỏi đó. Một ERD tương tác thì có cơ hội.
Search, filter, zoom, highlight không phải “nice to have”. Với database lớn, chúng là điều kiện để sơ đồ còn hữu ích.
CI mới là nơi tài liệu nên sống
Một command chạy local chỉ là demo. Quy trình thật phải nằm trong CI.
Ví dụ với tbls, bạn có thể sinh schema.json từ database, rồi để Liam ERD build giao diện tương tác từ file đó. Phần YAML cụ thể tôi để ở sample repo cuối bài, không nhồi vào đây. Điều quan trọng là bức tranh lớn:
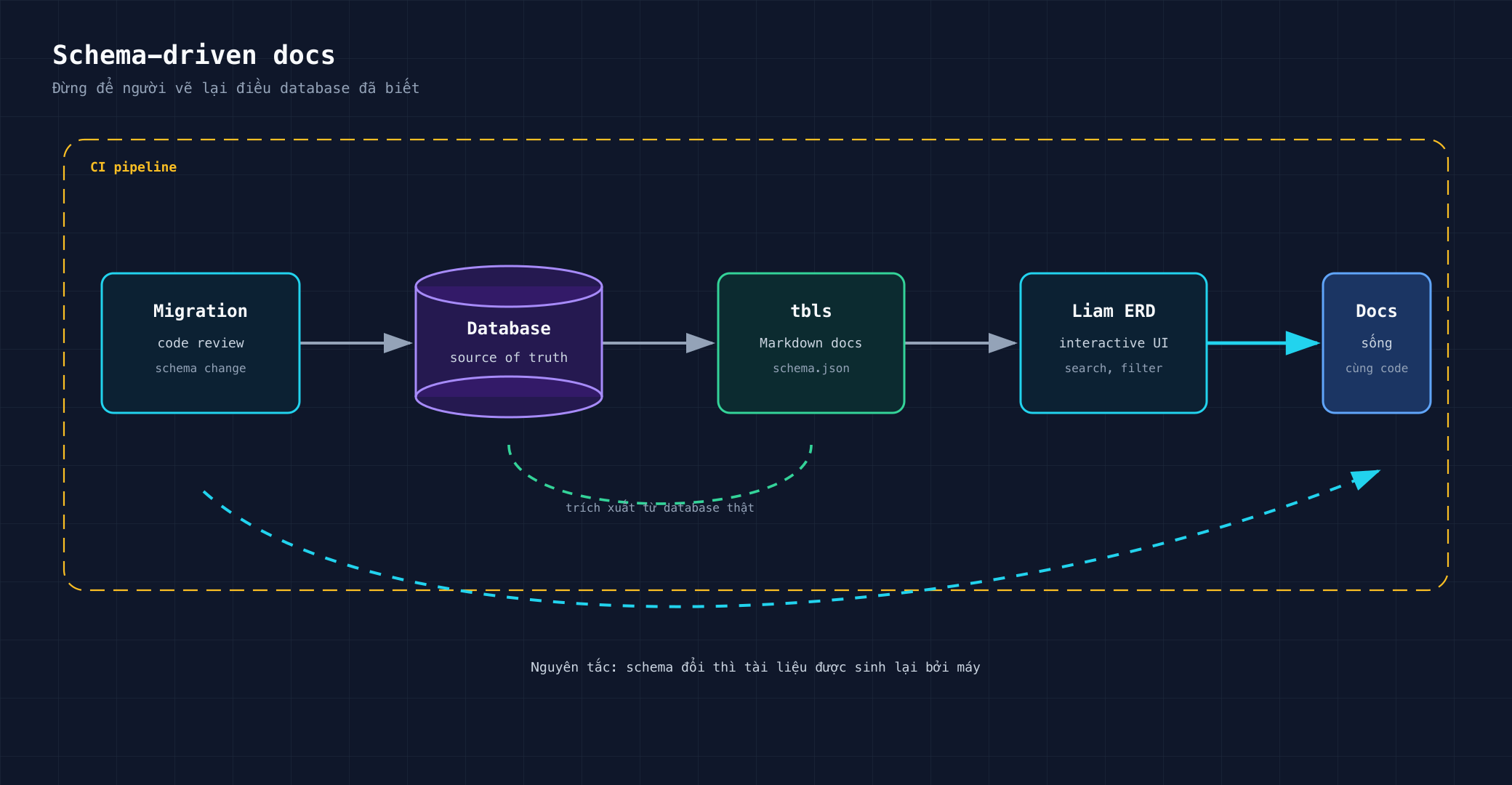
Code tạo schema. Schema tạo docs. Docs quay lại phục vụ review, onboarding và vận hành.
Với team khác, output có thể được publish lên GitHub Pages, Cloudflare Pages, S3 hoặc attach link preview vào pull request. Cách triển khai có thể đổi. Nguyên tắc không nên đổi: schema thay đổi thì tài liệu phải được sinh lại bởi máy.
Tài liệu database là giao diện giao tiếp
Tôi không xem ERD là “bản vẽ kỹ thuật”. Tôi xem nó là giao diện giao tiếp.
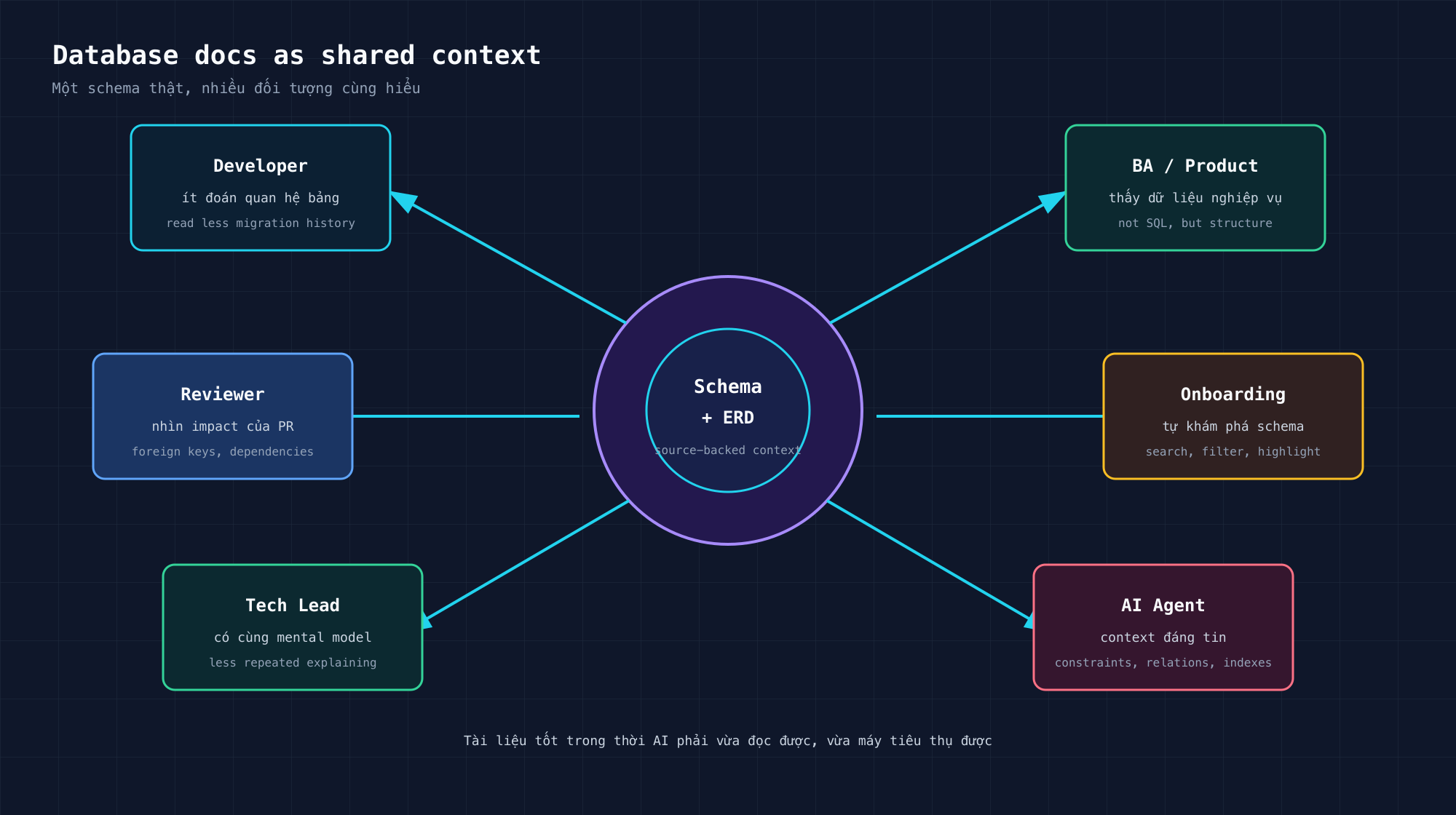
Một schema thật, nhiều đối tượng cùng đọc được theo nhu cầu của họ.
Giữa dev với dev, nó giảm thời gian đoán. Người mới không phải đọc 40 migration để hiểu một flow nghiệp vụ. Reviewer không phải dựng schema trong đầu khi đọc PR. Tech lead không phải giải thích cùng một quan hệ bảng trong năm buổi onboarding khác nhau.
Giữa dev với BA, nó tạo ra một hình ảnh chung. BA có thể không cần biết SQL, nhưng họ cần thấy dữ liệu nghiệp vụ đang bị chia ở đâu, nối ở đâu, và vì sao một thay đổi tưởng nhỏ lại kéo theo nhiều bảng.
Giữa dev với AI, nó còn quan trọng hơn.
LLM không thiếu khả năng viết code. Nó thiếu context đáng tin. Nếu bạn chỉ prompt “viết API tạo order”, AI sẽ đoán. Nếu bạn đưa vào schema thật, constraints thật, quan hệ thật, nullable fields thật, nó có cơ hội viết code gần hệ thống của bạn hơn.
Đó là lý do output như schema.json, markdown docs từ tbls, hoặc ERD sinh từ Liam không chỉ phục vụ con người. Chúng là nguồn context tốt cho AI agent trong dự án: audit schema, phát hiện thiếu index, giải thích quan hệ bảng, hoặc gợi ý refactor query.
Một tài liệu tốt trong thời AI không chỉ để đọc. Nó phải có thể được máy tiêu thụ.
Cái cần thay đổi là tiêu chuẩn của team
Tôi không nghĩ team nên hỏi: “Ai sẽ cập nhật ERD sau sprint này?”
Câu hỏi đúng hơn là: “Vì sao ERD không tự cập nhật khi schema đổi?”
Một hệ thống trưởng thành không phải hệ thống có thật nhiều tài liệu viết tay. Nó là hệ thống mà các artifact quan trọng được sinh ra gần sự thật nhất có thể.
Database schema đã là sự thật. Hãy để nó nói.
Mở terminal, lấy schema của dự án hiện tại, quăng vào Liam ERD. Nếu sơ đồ khiến bạn thấy hệ thống rối hơn bạn tưởng, đó không phải lỗi của công cụ. Đó là lần đầu tiên hệ thống đang nói thật với bạn.
Nếu bạn muốn xem stack này hoạt động trong một project Laravel thực tế, tham khảo sample repo này: